堆排序
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆是一个近似完全二叉树的结构,并同时满足堆性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
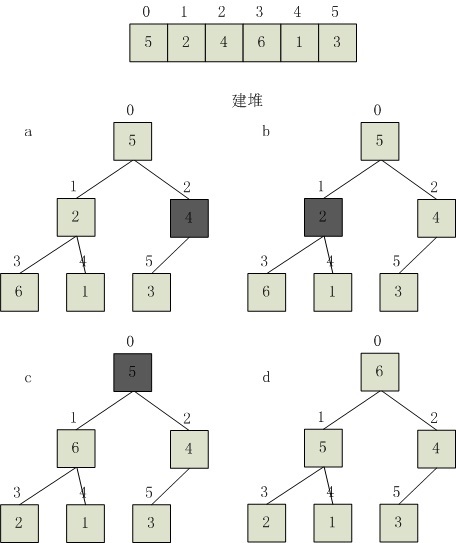
堆排序基本信息
| 中文名称 | 堆排序 | 外文名称 | Heap sort |
|---|---|---|---|
| 类别 | 排序算法 | 性质 | 即子结点的键值或索引总是小于(或者大于)它的父节点 |
堆排序原理分析
起源
1991年计算机先驱奖获得者、斯坦福大学计算机科学系教授罗伯特·弗洛伊德(Robert W.Floyd)和威廉姆斯(J.Williams)在1964年共同发明了著名的堆排序算法( Heap Sort )
“堆”定义
n个关键字序列Kl,K2,…,Kn称为(Heap),当且仅当该序列满足如下性质(简称为堆性质):
(1)ki<=k(2i)且ki<=k(2i+1)(1≤i≤ n),当然,这是小根堆,大根堆则换成>=号。//k(i)相当于二叉树的非叶结点,K(2i)则是左孩子,k(2i+1)是右孩子
若将此序列所存储的向量R[1..n]看做是一棵完全二叉树的存储结构,则堆实质上是满足如下性质的完全二叉树:
树中任一非叶结点的关键字均不大于(或不小于)其左右孩子(若存在)结点的关键字。
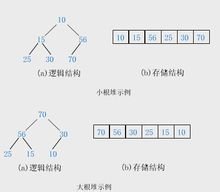
【例】关键字序列(10,15,56,25,30,70)和(70,56,30,25,15,10)分别满足堆性质(1)和(2),故它们均是堆,其对应的完全二叉树分别如小根堆示例和大根堆示例所示。
大根堆和小根堆:根结点(亦称为堆顶)的关键字是堆里所有结点关键字中最小者的堆称为小根堆,又称最小堆。根结点(亦称为堆顶)的关键字是堆里所有结点关键字中最大者,称为大根堆,又称最大堆。注意:①堆中任一子树亦是堆。②以上讨论的堆实际上是二叉堆(Binary Heap),类似地可定义k叉堆。
堆的高度
堆可以被看成是一棵树,结点在堆中的高度可以被定义为从本结点到叶子结点的最长简单下降路径上边的数目;定义堆的高度为树根的高度。我们将看到,堆结构上的一些基本操作的运行时间至多是与树的高度成正比,为O(lgn)。
堆排序
堆排序利用了大根堆(或小根堆)堆顶记录的关键字最大(或最小)这一特征,使得在当前无序区中选取最大(或最小)关键字的记录变得简单。
(1)用大根堆排序的基本思想
① 先将初始文件R[1..n]建成一个大根堆,此堆为初始的无序区
② 再将关键字最大的记录R[1](即堆顶)和无序区的最后一个记录R[n]交换,由此得到新的无序区R[1..n-1]和有序区R[n],且满足R[1..n-1].keys≤R[n].key
③由于交换后新的根R[1]可能违反堆性质,故应将当前无序区R[1..n-1]调整为堆。然后再次将R[1..n-1]中关键字最大的记录R[1]和该区间的最后一个记录R[n-1]交换,由此得到新的无序区R[1..n-2]和有序区R[n-1..n],且仍满足关系R[1..n-2].keys≤R[n-1..n].keys,同样要将R[1..n-2]调整为堆。
……
直到无序区只有一个元素为止。
(2)大根堆排序算法的基本操作:
① 初始化操作:将R[1..n]构造为初始堆;
② 每一趟排序的基本操作:将当前无序区的堆顶记录R[1]和该区间的最后一个记录交换,然后将新的无序区调整为堆(亦称重建堆)。
注意:
①只需做n-1趟排序,选出较大的n-1个关键字即可以使得文件递增有序。
②用小根堆排序与利用大根堆类似,只不过其排序结果是递减有序的。堆排序和直接选择排序相反:在任何时刻堆排序中无序区总是在有序区之前,且有序区是在原向量的尾部由后往前逐步扩大至整个向量为止
特点
堆排序(HeapSort)是一树形选择排序。堆排序的特点是:在排序过程中,将R[l..n]看成是一棵完全二叉树的顺序存储结构,利用完全二叉树中双亲结点和孩子结点之间的内在关系(参见二叉树的顺序存储结构),在当前无序区中选择关键字最大(或最小)的记录
堆排序与直接选择排序的区别
直接选择排序中,为了从R[1..n]中选出关键字最小的记录,必须进行n-1次比较,然后在R[2..n]中选出关键字最小的记录,又需要做n-2次比较。事实上,后面的n-2次比较中,有许多比较可能在前面的n-1次比较中已经做过,但由于前一趟排序时未保留这些比较结果,所以后一趟排序时又重复执行了这些比较操作。
堆排序可通过树形结构保存部分比较结果,可减少比较次数。
算法分析
堆排序的时间,主要由建立初始堆和反复重建堆这两部分的时间开销构成,它们均是通过调用Heapify实现的。
堆排序的最坏时间复杂度为O(nlogn)。堆序的平均性能较接近于最坏性能。
由于建初始堆所需的比较次数较多,所以堆排序不适宜于记录数较少的文件。
堆排序是就地排序,辅助空间为O(1),
它是不稳定的排序方法。
堆排序造价信息
C语言描述
// array是待调整的堆数组,i是待调整的数组元素的位置,nlength是数组的长度
void HeapAdjust(int array[],int i,int nLength)//本函数功能是:根据数组array构建大根堆
{ int nChild;
int nTemp;
for (nTemp = array; 2 * i + 1 < nLength; i = nChild)
{ // 子结点的位置=2*(父结点位置)+ 1
nChild = 2 * i + 1;
// 得到子结点中较大的结点
if (nChild < nLength - 1 && array[nChild + 1] > array[nChild])
++nChild;
// 如果较大的子结点大于父结点那么把较大的子结点往上移动,替换它的父结点
if (nTemp < array[nChild])
{ array= array[nChild];}
else // 否则退出循环
{ break;}// 最后把需要调整的元素值放到合适的位置
array[nChild]= nTemp;}
// 堆排序算法
void HeapSort(int array[],int length)
{ // 调整序列的前半部分元素,调整完之后第一个元素是序列的最大的元素
for (int i = length / 2 - 1; i >= 0; --i)
{ HeapAdjust(array,i,length);}
// 从最后一个元素开始对序列进行调整,不断的缩小调整的范围直到第一个元素
for (int i = length - 1; i > 0; --i)
{ // 把第一个元素和当前的最后一个元素交换,
// 保证当前的最后一个位置的元素都是在现在的这个序列之中最大的
Swap(&array[0],&array);
// 不断缩小调整heap的范围,每一次调整完毕保证第一个元素是当前序列的最大值
HeapAdjust(array,0,i);}
堆排序算法(C++描述)
#define MAX 100//数据元素的最大个数
typedef struct
{
int r[MAX];
int length;
}SqList;//定义一个线性表用于存放数据元素
void HeapAdjust(SqList &L,int s,int m)
{//已知L.r[s...m]中记录除L.r[s]外均满足堆的定义,本函数用于使L.r[s...m]成为一个大顶堆
int j;
int e=L.r[s];
for(j=2*s;j<=m;j*=2)
{
if(j<M&&L.R[J]<L.R[J+1]) ++j;
if(e>=L.r[j]) break;
L.r[s]=L.r[j];
s=j;
}
L.r[s]=e;
}
void HeapSort(SqList &L)
{//对顺序表L进行堆排序
int i,e;
for(i=L.length/2;i>0;i--)
HeapAdjust(L,i,L.length);
for(i=L.length;i>1;i--)
{//将大顶堆的顶记录和最后一个记录相互交换
e=L.r[1];
L.r[1]=L.r;
L.r=e;
HeapAdjust(L,1,i-1);
}
}
因为构造初始堆必须使用到调整堆的操作,先讨论Heapify的实现,再讨论如何构造初始堆(即BuildHeap的实现)Heapify函数思想方法
每趟排序开始前R[l..i]是以R[1]为根的堆,在R[1]与R交换后,新的无序区R[1..i-1]中只有R[1]的值发生了变化,故除R[1]可能违反堆性质外,其余任何结点为根的子树均是堆。因此,当被调整区间是R[low..high]时,只须调整以R[low]为根的树即可。
"筛选法"调整堆
R[low]的左、右子树(若存在)均已是堆,这两棵子树的根R[2low]和R[2low+1]分别是各自子树中关键字最大的结点。若R[low].key不小于这两个孩子结点的关键字,则R[low]未违反堆[性质,以R[low]为根的树已是堆,无须调整;否则必须将R[low]和它的两个孩子结点中关键字较大者进行交换,即R[low]与R[large](R[large].key=max(R[2low].key,R[2low+1].key))交换。交换后又可能使结点R[large]违反堆性质,同样由于该结点的两棵子树(若存在)仍然是堆,故可重复上述的调整过程,对以R[large]为根的树进行调整。此过程直至当前被调整的结点已满足性质,或者该结点已是叶子为止。上述过程就象过筛子一样,把较小的关键字逐层筛下去,而将较大的关键字逐层选上来。因此,有人将此方法称为"筛选法"。
BuildHeap的实现
要将初始文件R[l..n]调整为一个大根堆,就必须将它所对应的完全二叉树中以每一结点为根的子树都调整为堆。
显然只有一个结点的树是堆,而在完全二叉树中,所有序号大于n/2的结点都是叶子,因此以这些结点为根的子树均已是堆。这样,我们只需依次将以序号为n/2,…,1的结点作为根的子树都调整为堆即可。
Heapify函数算法实例
#include
#include
inline int LEFT(int i);
inline int RIGHT(int i);
inline int PARENT(int i);
void MAX_HEAPIFY(int A[],int heap_size,int i);
void BUILD_MAX_HEAP(int A[],int heap_size);
void HEAPSORT(int A[],int heap_size);
void output(int A[],int size);
int main()
{
FILE *fin;
int m,size,i;
fin = fopen("arrayin","r");
int* a;
fscanf(fin," %d",&size);
a = (int *)malloc(size + 1);
a[0]=size;
for(i = 1;i <= size; i++ )
{
fscanf(fin," %d",&m);
a= m;
}
HEAPSORT(a,a[0]);
printf("$$$$$$$$$$The Result$$$$$$$$\n");
output(a,a[0]);
free(a);
return 0;
}
inline int LEFT(int i)
{
return 2 * i;
}
inline int RIGHT(int i)
{
return 2 * i + 1;
}
inline int PARENT(int i)
{
return i / 2;
}
void MAX_HEAPIFY(int A[],int heap_size,int i)
{
int temp,largest,l,r;
largest = i;
l = LEFT(i);
r = RIGHT(i);
if ((l <= heap_size) && (A[l] > A[largest])) largest = l;
if ((r<= heap_size) && (A[r] > A[largest])) largest = r;
if (largest != i)
{
temp = A[largest];
A[largest] = A;
A= temp;
MAX_HEAPIFY(A[],heap_size,largest);
}
}
void BUILD_MAX_HEAP(int A[],int heap_size)
{
int i;
for (i = heap_size / 2;i >= 1;i--) MAX_HEAPIFY(A,heap_size,i);
}
void HEAPSORT(int A[],int heap_size)
{
int i;
BUILD_MAX_HEAP(A,heap_size);
for (i = heap_size;i >= 2; i--)
{
int temp;
temp = A[1];
A[1] = A;
A= temp;
MAX_HEAPIFY(A,i-1,1);
}
}
void output(int A[],int size)
{
int i = 1;
FILE *out = fopen("resultin","w+");
for (; i <= size; i++)
{
printf("%d ",A);
fprintf(out,"%d ",A);
}
printf("\n");
}
Pascal/Delphi描述
const
max=100;
type
arr=array[1..max] of integer;
var
a:arr;
i,n,temp:integer;
procedure heap(var r:arr;nn,ii:integer); //之所以重新定义r数组而不是在a数组上修改,是为了能同时操作不同的数组
var
x,i,j:integer;
begin
i:=ii;
x:=r[ii];//把待调整的节点值暂存起来。
j:=ii shl 1;//j 为 ii 的左孩子编号,初始时假设它比右孩子的值大。
while j<=nn do
begin
if (j+1<nn) and (r[j]<r[j+1]) then //必须是j+1,因为j=nn时,j+1>nn,会影响已排过的节点!
inc(j);//j 为值大的那个孩子的节点编号。
if x<r[j] then//调整。
begin
r:=r[j];
i:=j;
j:=i shl 1
end
else j:=nn+1//故意让 j 超出范围,终止循环。
end;
r:=x;//调整到最终位置。
end;
begin
readln(n);
for i:=1 to n do
read(a);
writeln;
for i:=n shr 1 downto 1 do
heap(a,n,i);//建立初始堆,且产生最大值 A[1]。
for i:=n downto 2 do//将当前最大值交换到最终位置上,再对前 i-1 个数调整。
begin
temp:=a[1];
a[1]:=a;
a:=temp;
heap(a,i-1,1)
end;
for i:=1 to n do
write(a:4)
end.
C#描述
#region 堆
///
/// 建成大堆
///
///
///
///
void HeapAdjust(int[] arr,int i,int length)
{
int child = 2 * i + 1; //左节点
int temp = arr; //中间变量保存当前根节点
while (child < length)
{
//如果有右节点,判断是否大于左节点
if (child < length - 1 && arr[child] < arr[child + 1])
child++;
//双亲节点大于子节点
if (temp >= arr[child])
break; //不需调整,结束调整
arr = arr[child]; //双亲结点值设置为大的子节点值
i = child;
child = 2 * i + 1;
}
arr = temp;
}
public void Heap(int[] arr)
{
//第一次创建大堆
for (int i = arr.Length / 2 - 1; i >= 0; i--)
{
HeapAdjust(arr,i,arr.Length);
}
//元素位置调换
for (int i = arr.Length - 1; i > 0; i--)
{
//堆顶与当前堆的最后一个堆元素交换位置
int tmp = arr[0];
arr[0] = arr;
arr = tmp;
//将剩下的无序堆部分重新建堆处理
HeapAdjust(arr,0,i);
foreach (int v in arr)
{
Console.Write(v.ToString() + " ");
}
Console.WriteLine("");
}
}
#endregion
Pascal描述
var
i,n:integer;
a:array[0..100] of integer;
procedure swap(var a,b:integer);
var t:integer;
begin t:=a;a:=b;b:=t;
end;
procedure heapsort(i,m:integer);
var t:integer;
begin
t:=i*2;
while t<=m do
begin
if (t<m) and (a[t]>a[t+1]) then inc(t);
if a>a[t] then begin swap(a,a[t]);i:=t;t:=2*i; end
else break;
end;
end;
begin
readln(n);
for i:=1 to n do read(a);
for i:=n div 2 downto 1 do heapsort(i,n);
for i:=n downto 2 do
begin
write(a[1],' ');
a[1]:=a;
heapsort(1,i-1);
end;
writeln(a[1]);
end.
JAVA描述
public class HeapSortTest {
/*
* 将数组调整为小根堆,即由小到大排序
*/
public static int[] heap = new int[] { 1,3,7,5,2,8,4,6,10,9};
public static void main(String[] args) {
int temp;
/*
* 创建堆(对该堆进行简单的排序)
*/
CreateHeap();
for (int i = heap.length - 1; 0 < i; i--) {
temp = heap[0];
heap[0] = heap;
heap = temp;
/*
* 展示每次排序后的结果
*/
for (int j = 0; j < heap.length; j++) {
System.out.print(heap[j] + " ");
}
System.out.println();//换行
/*
* 从堆顶进行调整,使未排序堆中最大关键字到堆顶
*/
AdjustHeap(0,i);
}
}
/*
* 调整堆使其堆顶为未排序堆中最大关键字
*/
public static void AdjustHeap(int location,int unSortlength) {
int temp;
int tempLoc;
/*
* 确保左右节点存在
*/
if ((tempLoc = (location + 1) * 2) < unSortlength) {
/*
* 判断左右节点大小
*/
if (heap[tempLoc] >= heap[tempLoc - 1]) {
/*
* 判断父节点与子节点的大小,若父节点小,则与大的子节点换位
*/
if (heap[location] < heap[tempLoc]) {
temp = heap[location];
heap[location] = heap[tempLoc];
heap[tempLoc] = temp;
/*
* 递归法对换位后的子节点及其子节点进行调整
*/
AdjustHeap(tempLoc,unSortlength);
}
} else {
/*
* 左节点大于右节点
*/
if (heap[location] < heap[tempLoc - 1]) {
temp = heap[location];
heap[location] = heap[tempLoc - 1];
heap[tempLoc - 1] = temp;
/*
* 递归法对换位后的子节点及其子节点进行调整
*/
AdjustHeap(tempLoc - 1,unSortlength);
}
}
}
/*
* 确保左节点存在
*/
else if ((tempLoc = (location + 1) * 2 - 1) < unSortlength) {
/*
* 与左节点进行比较
*/
if (heap[location] < heap[tempLoc]) {
/*
* 左子节点大于父节点,将两者进行换位
*/
temp = heap[location];
heap[location] = heap[tempLoc];
heap[tempLoc] = temp;
AdjustHeap(tempLoc,unSortlength);
}
}
}
/*
* 创建堆(对该堆进行简单的排序)
*/
public static void CreateHeap() {
for (int i = heap.length - 1; i >= 0; i--) {
AdjustHeap(i,heap.length);
}
}
}
c++描述
/* 这是经过优化的代码。一般都用大根堆,但是如果用小根堆实现,每次都将最小的元素放到最后一个,可以省一半空间。用c数组是因为我写一道题目需要给c数组排序……直接粘过去,偷懒一下 &^_^& */
#include<iostream>
using namespace std;
int c[1000];
int n,m;
void check(int i)
{
int min;
if(m>=i*2+1) //不能用n,因为需要排序的元素个数在不断变化
{
if(c[i*2+1]<c[i*2])
min=i*2+1;
else
min=i*2;
if(c[min]<c)
{
swap(c,c[min]);
check(min);
}
} //这几行也可以换成判断然后交换c和c[i*2+1],又可以省去几行。哈哈。
else
if(m>=i*2 && c[i*2]<c)
{
swap(c[i*2],c);
check(i*2);
}
}
//check函数用来维持小根堆
void tree()
{
m=n;
for(int i=m/2;i>=1;i--)
check(i);
while(m!=1)
{
swap(c[1],c[m]); //将最小的元素放到最后,这个元素以后的元素就是有序的,不用参加排序了
m--;
check(1);
}
}
//tree函数用来建堆
int main()
{
cin>>n;
for(int i=1;i<=n;i++)
cin>>c;
tree();
for(i=1;i<=n;i++)
cout<<c<<' ';
cout<<endl;
system("pause"); //为了方便观察结果才写的这一行,提交题目的时候一定要删掉!!!
return 0;
}
AAuto语言描述
io.open();//打开控制台
/*
*-------------------------------------------------------
* 堆排序( 原地排序 )
*-------------------------------------------------------
*/
/*
二叉堆是完全二叉树。
索引总是以2倍的形式递增,从上到下从左到右顺序递增
[1]
∧
[2] [3]
∧ ∧
[4] [5] [6] [7]
因此可以用数组来表示二叉堆。
设 heap= {}
heap[1] = 29;
heap[2] = 19;
heap[3] = 18;
heap[4] = 9;
heap[5] = 8;
heap[6] = 7;
heap[7] = 6;
则 heap如下排列 {29;19;18;9;8;7;6}
29
∧
19 18
∧ ∧
9 9 7 6
二叉堆有小根堆,大根堆,大根堆最大的元素在顶部,所有元素按索引排序。
*/
getParentIndex = function(i){
//二叉堆的父子索引总是以2倍的形式递增、堆左边索引是2的n次方。
return math.floor(i/2)//所以除2总是能向上倒退一层到父节点的索引。
}
getLeftNodeIndex = function(i){
//父层到子层,总是一变二,所以索引也增加2倍
return 2*i
}
getRightNodeIndex = function(i){
return 2*i+1
}
/*
假定一个数组A的元素i,假定getLeftNodeIndex,getRightNodeIndex都是最大堆。
如果array小于其子女,则调节array,使之下降。
*/
max_heapify = function(array,i){
var l = getLeftNodeIndex(i);
var r = getRightNodeIndex(i);
var largest;
if( ( l<=array.heapsize ) and( array[l] > array) )
largest = l;//左子树比较大
else{
largest = i;//父节点比较大
}
if( ( r<=array.heapsize ) and( array[r] > array[largest]) )
largest = r;//右子树比较大
//如果array小于其子女,则调节array,使之下降。
if( largest != i){
var exchange = array
array = array[largest]
array[largest] = exchange;
max_heapify(array,largest);//现在子树largest是最大的了
}
}
/*
对于数组A,最后一个页节点索引为#A
#A的父节点为 math.floor(#A/2) ,而且是最后一个父节点。而之后都是叶节点。
因此,我们从最后一个父节点开始,从右至左,自下而上调用max_heapify检查所有的堆。使之符合二叉堆定义.
如此:小的通过max_heapify函数的递归调用一降到底,大的数通过build_max_heap的for循环逐步上升到顶,清升而浊降。
*/
//建堆
build_max_heap = function(array){
array.heapsize = #array;
for(i=math.floor(#array/2);1;-1){
max_heapify(array,i);
}
}
/*
堆建好了,根节点一定比子结点大。
但是左边的不一定比右边的大,因为二叉堆不比较左右子树。
而且在不同的子二叉堆里,他们也没有排序关系
io.print( table.tostring(array) ) //输出看一下,整体上仍然是乱的
*/
/*
堆虽然不是完全线性有序的数组,但是根节点总是最大的元素。
通常用于实现 高效的优先级队列
*/
//那么下面我们要利用建好的堆来排序
heap_sort = function(array){
build_max_heap(array)//建堆
//现在array[1]是根节点了,并且一定是最大的
//我们把最大的放在数组最右侧,后把最右侧较小的元素放到根节点来破坏二叉堆,再用max_heapify来修复堆取到下一个最大的数
//不断循环此过程,不断的将最大的元素移到右侧,而堆向左收缩,就达到了排序的效果
for(sorted=#array;2;-1){
var max = array[1]
array[1] = array[sorted] //把小的移到二叉堆的顶部来破坏堆定义
array[sorted] = max;//把最大的移到右侧已排序的数组中
array.heapsize--;
max_heapify(array,1);//修复二叉堆根节点,取下一个最大数
}
}
//终于排序好了输出看一下
io.print("----------------")
io.print("堆排序")
io.print("----------------")
array ={2;46;5;17;1;2;3;99;12;56;66;21};
heap_sort(array)
//输出结果
for(i=1;#array;1){
io.print( array )
}
/*
排序算法的稳定性:保证排序前2个相等的数其在序列的前后位置顺序和排序后它们两个的前后位置顺序相同
稳定排序算法:冒泡排序 插入排序 合并排序
不稳定排序算法:堆排序 快速排序
*/
execute("pause") //按任意键继续
io.close();//关闭控制台
js语言描述
//5000个无序随机里取最大的50个数
//定义
var heap={};
//大数组,从1-1000000取5000个随机数
heap.arr=[];
for(var i=0;i<5000;i++){
heap.arr.push(Math.floor(1000000*Math.random())+1);
}
//取前50个数作为堆
heap.arrTemp=heap.arr.slice(0,50).sort(function(a,b){
return a-b;
});
//无序数组里挨个与堆的最小数判断,大则入堆,堆重新排序,返回50个最大的数
heap.j=50;
(function(){
while(heap.j<5000){
if(heap.arr[heap.j]>heap.arrTemp[0]){
heap.arrTemp.splice(0,1,heap.arr[heap.j]);
heap.arrTemp.sort(function(a,b){
return a-b;
});
}
heap.j++;
}
return heap.arrTemp;
})();
堆排序常见问题
-
击【分部整理】,会显示下方窗口,如图一: 钩选分部规则后点击“执行分部整理”即可。 点击【分部整理】,会显示下方窗口,如图二: 点击“执行子目排序”即可
-
使用08定额,建筑与装饰最好分开(分两个预算)做,就不会出现借用定额的代号了,直接点分部整理即可排序,如果不想分为两个预算,装饰部分可以按鼠标右键插入分部输入编号、分部名称,然后将该分部的子目用上下移...
-
你是说的定义构件中的构件排序吧,具体子类型是什么也搞不清,但排序最好是选择【按子类型和名称】排序最适当,我试过其它排序,混乱、不好使。
堆排序文献

 第8章排序介绍
第8章排序介绍
第 8 章 排序 1.选择题 ( 1)从未排序序列中依次取出元素与已排序序列中的元素进行比较, 将其放入已排序序 列的正确位置上的方法,这种排序方法称为( )。 A.归并排序 B.冒泡排序 C.插入排序 D.选择排序 答案: C ( 2)从未排序序列中挑选元素,并将其依次放入已排序序列(初始时为空)的一端的方 法,称为( )。 A.归并排序 B.冒泡排序 C.插入排序 D.选择排序 答案: D ( 3)对 n 个不同的关键字由小到大进行冒泡排序,在下列( )情况下比较的次数最 多。 A.从小到大排列好的 B.从大到小排列好的 C.元素无序 D.元素基本有序 答案: B 解释:对关键字进行冒泡排序,关键字逆序时比较次数最多。 ( 4)对 n 个不同的排序码进行冒泡排序, 在元素无序的情况下比较的次数最多为 ( )。 A. n+1 B. n C. n-1 D. n(n-1)/2 答案:
 第8章排序总结
第8章排序总结
第 8 章 排序 1.选择题 ( 1)从未排序序列中依次取出元素与已排序序列中的元素进行比较, 将其放入已排序序 列的正确位置上的方法,这种排序方法称为( )。 A.归并排序 B.冒泡排序 C.插入排序 D.选择排序 答案: C ( 2)从未排序序列中挑选元素,并将其依次放入已排序序列(初始时为空)的一端的方 法,称为( )。 A.归并排序 B.冒泡排序 C.插入排序 D.选择排序 答案: D ( 3)对 n 个不同的关键字由小到大进行冒泡排序,在下列( )情况下比较的次数最 多。 A.从小到大排列好的 B.从大到小排列好的 C.元素无序 D.元素基本有序 答案: B 解释:对关键字进行冒泡排序,关键字逆序时比较次数最多。 ( 4)对 n 个不同的排序码进行冒泡排序, 在元素无序的情况下比较的次数最多为 ( )。 A. n+1 B. n C. n-1 D. n(n-1)/2 答案:
堆排序相关推荐
- 相关百科
- 相关知识
- 相关专栏
- 泽漆
- 平衡树
- 伊立浦CFXB30-52(P)
- 奥克斯FC-40E
- 蒙古蒿
- Treap
- 中序遍历
- 华南马尾杉
- RSPS系列零压差蒸汽阀
- AVL
- 逆波兰式
- 尚朋堂SC-Y401D
- 数据结构与算法分析
- 线段树
- ProENGINEERWildfire3.0基础实例
- 地刷子石松
- 基于压电堆驱动器的喷嘴挡板式气体控制阀
- 电气工程及其自动化特色专业建设探索
- 分形DGS单元结构设计及其在微带电路中的应用
- 磷铵技术改造五大磷肥工程的建议
- 以大豆油多元醇制备的硬质聚氨酯泡沫塑料的性能
- 逆变TIG焊机接触引弧电路的设计(引弧电路)
- 预制砌块(砖、石)挡土墙工程砌体施工安全技术交底
- 应用模糊数学理论对公路工程建设项目方案的综合评价
- 引嫩工程扩建区土壤水盐动态与防治土壤盐碱措施
- 中华华丹雨、污水管道沟槽开挖专项施工方案教学教材
- 中国工程图学学会成立工程与制造系统集成化分会
- 中国吹制玻璃行业市场前景分析预测年度报告(目录)
- 可替代现有隔热保温材料的新型材料
- 医院病房楼工程施工装饰装修工程施工控制
- 在生活中构筑自然——河南天旺园林工程有限公司剪影
- 中国机械工程学会授予材料热处理工程师资格人员名单
最新词条
安徽省政采项目管理咨询有限公司
数字景枫科技发展(南京)有限公司
怀化市人民政府电子政务管理办公室
河北省高速公路京德临时筹建处
中石化华东石油工程有限公司工程技术分公司
手持无线POS机
广东合正采购招标有限公司
上海城建信息科技有限公司
甘肃鑫禾国际招标有限公司
烧结金属材料
齿轮计量泵
广州采阳招标代理有限公司河源分公司
高铝碳化硅砖
博洛尼智能科技(青岛)有限公司
烧结刚玉砖
深圳市东海国际招标有限公司
搭建香蕉育苗大棚
SF计量单位
福建省中亿通招标咨询有限公司
泛海三江
威海鼠尾草
Excel 数据处理与分析应用大全
广东国咨招标有限公司
甘肃中泰博瑞工程项目管理咨询有限公司
山东创盈项目管理有限公司
当代建筑大师
广西北缆电缆有限公司
拆边机
大山槟榔
上海地铁维护保障有限公司通号分公司
甘肃中维国际招标有限公司
舌花雏菊
湖北鑫宇阳光工程咨询有限公司
GB8163标准无缝钢管
中国石油炼化工程建设项目部
华润燃气(上海)有限公司
韶关市优采招标代理有限公司
莎草目
建设部关于开展城市规划动态监测工作的通知
电梯平层准确度
广州利好来电气有限公司
四川中泽盛世招标代理有限公司